The Hermes Agent Memory Guidebook
Native memory, MemoryProviders, and community memory plug-ins for Hermes Agent.
By Kevin Simback · Published on X, May 23, 2026
Source: https://x.com/KSimback/status/2058262328496554021

TLDR: this is your definitive guide to all things related to memory systems for Hermes Agent. Why create this? Because every week I see new posts or articles describing some new memory tool for Hermes agents and these make me question if my memory setup is the best. So I dug into all of them and broke it down for you.
Over the past few months my Hermes agent has been mapping the Hermes ecosystem over at hermesatlas.com. One of the key areas it has covered is memory and it even has a dedicated memory providers section for it.

And let's be honest, there are a LOT of memory related tools available and there are a LOT of write-ups about them. I see new articles on X every week about some new memory setup. It's hard to keep up, and even harder to know if you're doing it all wrong because they all make claims about how certain memory systems are better than others.
But many of these write-ups skip the architecture (how memory works in Hermes) or conflate different elements of the memory stack. This article is the culmination of everything I've learned about Hermes agent memory and a guide to help you navigate what makes most sense for your setup.
Memory is arguably the most important element of an agent setup
Without memory, an agent is just a stateless function and no different than a blank ChatGPT window. Every prompt looks like the first prompt. That works for one-shot questions but breaks down the moment you have a use case that needs to know what happened yesterday, remember your preferences, accumulate skills from prior tasks, or coordinate with another agent.
A coding session that doesn't remember the conventions you established last Tuesday will reinvent them this Tuesday. A personal assistant agent that doesn't remember your preferences has to ask you the same repeated questions. Without memory, an agent really isn't an agent at all.
Memory is what turns an chatbot into something that compounds. Which is why every serious agent harness - OpenClaw, Claude Code, Codex, and our beloved Hermes Agent - has memory primitives built in, and why a real product category has emerged around dedicated memory infrastructure or agents (Mem0 raised $24M, Letta $10M, plus Zep, Cipher, Supermemory, Hindsight, etc.).
The Hermes Agent take is interesting because Nous Research treats memory as first-class plug-in infrastructure, not a feature. There's a base layer that always runs, a pluggable provider system that lets you choose from 8 architectures (or write your own), and a healthy community plug-in layer on top.
That 3-layer stack is what I will explore in depth in this article.
Hermes Agent memory architecture at a glance
Here's what each layer means for you as a Hermes user.
Layer 1 - what ships in the box. You get this whether you do anything or not. Two small markdown files the agent uses as its always-visible notebook, plus a local database that archives every session you've ever had. No setup, no config. For many use cases, this is often all you need.
Layer 2 - the optional plug-in slot. When you outgrow the native layer (you want semantic recall across sessions, or a system that models your preferences, or token-efficient retrieval at scale) you pick one of 8 official providers. They each take a different architectural bet about what memory should do, and you can run exactly one at a time. Switching providers is a clean start - the new provider doesn't inherit the old one's data, but the Layer 1 native files keep running underneath either way.
Layer 3 - what the community builds beyond the official 8. Two flavors. Some community projects are MemoryProvider plug-ins that compete head-to-head with the Layer 2 picks (Mnemosyne is the standout - fully local, sub-millisecond, with a real tiered cognitive architecture). Others sit alongside the official providers in a different slot entirely (GBrain is the standout here - it stores world facts like people, companies, and projects in a markdown vault, while your Layer 2 provider handles operational memory). Layer 3 usually means more setup and less polish than the official 8, but it's where you go when you need a capability the eight providers don't offer.
The layers stack rather than replace each other. Switching the Layer 2 provider does not wipe Layer 1. Each provider has its own store, but the native session database and the two markdown files keep running underneath. Layer 3 plug-ins are additive on top of both.
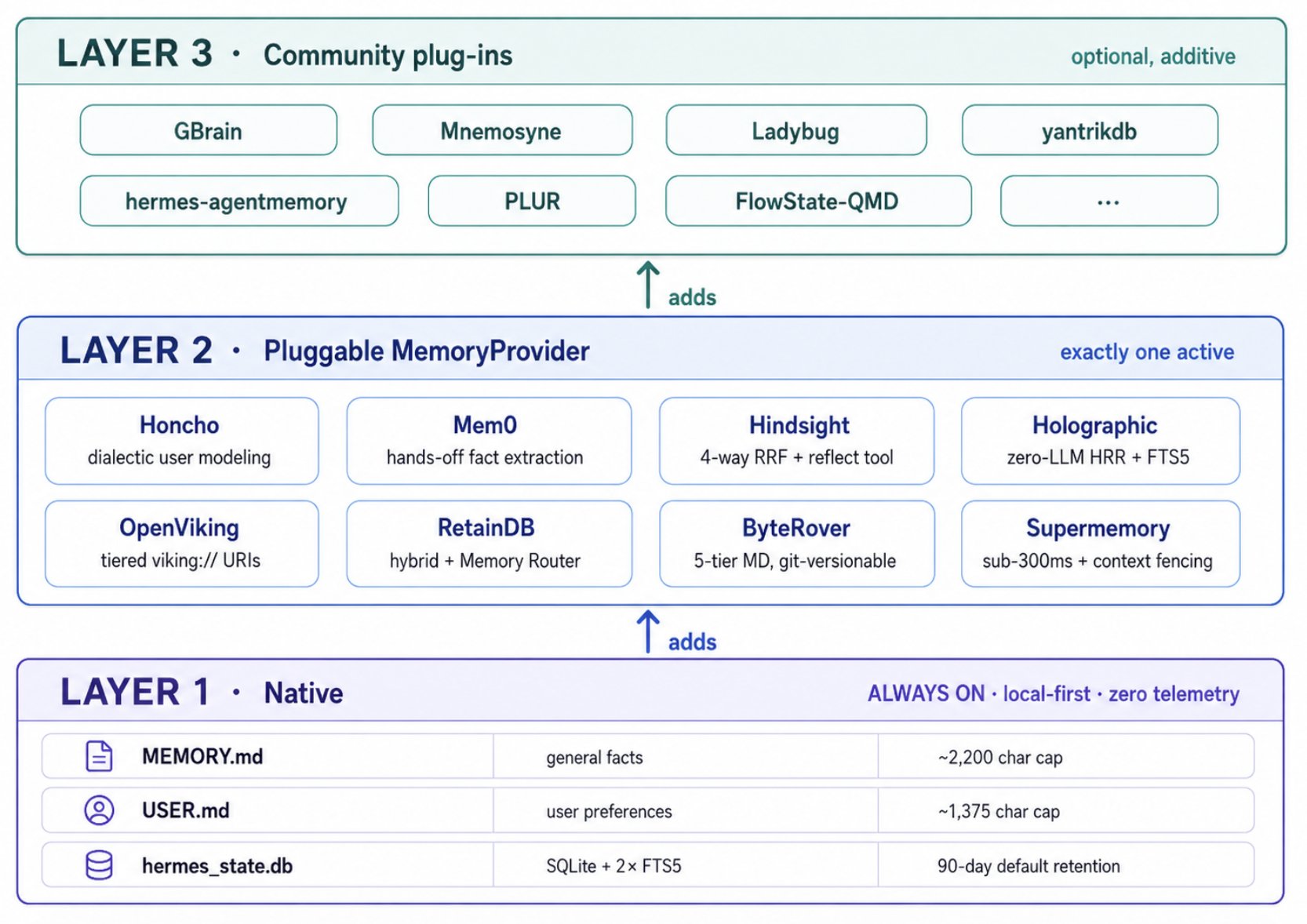
Layer 1: Native - what you get out of the box
The native layer is three things that ship with every Hermes install: two small markdown files and one database. They play different roles, and it's worth understanding each before we get to the plug-in providers.
Note: if you already understand the out of box setup or want to skip to the optional stuff you can install on top, go to Layer 2.
The two markdown files
When you install Hermes, it creates two text files in your home directory at ~/.hermes/:
MEMORY.md - the agent's general knowledge notebook. Project context, technical decisions, things worth remembering across sessions. Capped at about 2,200 characters, roughly a paragraph and a half.
USER.md - what the agent knows about you specifically. Your preferences, your working style, your role. Capped at about 1,375 characters, roughly one paragraph.
You can open both files in any text editor. They're plain markdown. You can even edit them by hand if you want, and the agent will read your edits next session.
The reason they're so small is that they aren't the agent's filing cabinet - they're the agent's sticky notes. At the start of every session, Hermes pastes the entire contents of both files into the prompt sent to the model. So everything in these files is always "in front of" the agent. No retrieval needed, it just sees them.
The agent itself decides what goes into these files. When something important comes up in a session - you say "I prefer bullet points instead of paragraphs" or the agent figures out that you use Vercel for deployments - the agent calls a tool called memory with one of three actions: add, replace, or remove. There's no read action because the files are already pasted into the prompt; the agent reads them by virtue of looking at its own context.
What happens when the files fill up?
This is where most third-party write-ups get things wrong. They claim Hermes automatically consolidates the files when they hit 80% of the cap. I went into the code at agent/memory_manager.py to verify, and the actual behavior is more interesting:
There is no automatic consolidation - the 80% rule is a prompt instruction, not code. The system prompt header shows the agent a real-time fill gauge - something like "MEMORY: 1,847/2,200 chars (84 percent)" - along with the instruction "when memory is above 80% capacity, consolidate entries before adding new ones." The agent reads that, and the agent decides whether to act on it. If the file is already at the cap and the agent tries to add anything anyway, the memory tool returns an error listing the current entries and forces the agent to free space via replace or remove first.
This is a deliberate design choice. Nous trusts the model to manage its own notebook. The upside is full agent control, but the downside is also full agent control. A poorly-prompted agent can sit at the cap indefinitely, refusing every new add call and quietly losing information that should have replaced something older, but I'm confident this gets resolved soon as there's some PRs around this.
A related point of confusion worth clearing up before we go on: v0.12 introduced something called the "Autonomous Curator" and many write-ups describe it as automatic memory management. It is not. The Curator operates only on the agent's skill library at ~/.hermes/skills/ - moving skills from active to stale to archived based on usage. It never touches MEMORY.md or USER.md.
The database (and how it relates to the markdown files)
The two markdown files are the agent's always-visible notes. The database is the agent's full archive of everything that has ever happened.
Hermes stores every session in a SQLite database file at ~/.hermes/hermes_state.db. Every user message, every agent response, every tool call, every reasoning step, plus economic data like token counts and dollar cost per session - all of it lands here. Default retention is 90 days; older sessions get pruned automatically every 24 hours unless you change the setting.
This database is not auto-injected into prompts. It would be enormous - imagine pasting your entire chat history into every new conversation. Instead, the agent searches it on demand when it needs to find something specific.
The search uses SQLite's built-in full-text search (FTS5), and Hermes maintains two parallel indexes: one for normal word-level search ("did we discuss the content strategy?") and one for trigram search that handles substrings and code tokens ("find every session where I mentioned github").
So the mental model is:
The two markdown files = what the agent always has in its head. Small, curated, always present in every prompt.
The session database = what the agent can look up if it knows what to look for. Huge, raw, searchable on demand.
These are complementary, not redundant. When something matters across all future sessions, the agent should write it to MEMORY.md so it's always present. When something might matter again but doesn't need to be top-of-mind, it lives in the session database and gets pulled up only when the agent searches for it.
A nice side-effect of the database design: because Hermes captures every reasoning step and every tool call with full economic data, the database is also a complete training trajectory if you ever want to export it. This is beyond the scope of this article but something that aligns with my thesis on where the moats are in agents.
Layer 2: The pluggable "MemoryProvider" system
This is the layer that lets you graduate from "small notebook plus searchable archive" to a real memory system - one that extracts facts from your conversations automatically, builds a profile of you, supports semantic recall across sessions, or handles a large knowledge graph.
Setting this up is quite simple - you run "hermes memory setup", pick a provider from the menu, and from then on the agent has a richer memory layer to draw from on top of the native files. Note: some providers require API keys and paid plans.
The important note is you can only run one provider at a time. Hermes treats this as a single deliberate choice, not a stack of bolt-ons.
That keeps your tool surface clean - each provider exposes its own set of agent tools, and the agent would get confused if there were three competing "search memory" tools sitting in front of it - and it makes the configuration easy to reason about. The Layer 1 native files keep running underneath whether you have a provider active or not.
Picking the right provider matters because they make very different architectural bets. Some are aggressive at extracting facts. Some build a model of how you think rather than what you said. Some are obsessed with token efficiency. Some are graph-first. The full decision tree is later in this article; the technical mechanics below are for readers who want to know what providers actually plug into.
Let's dive in.
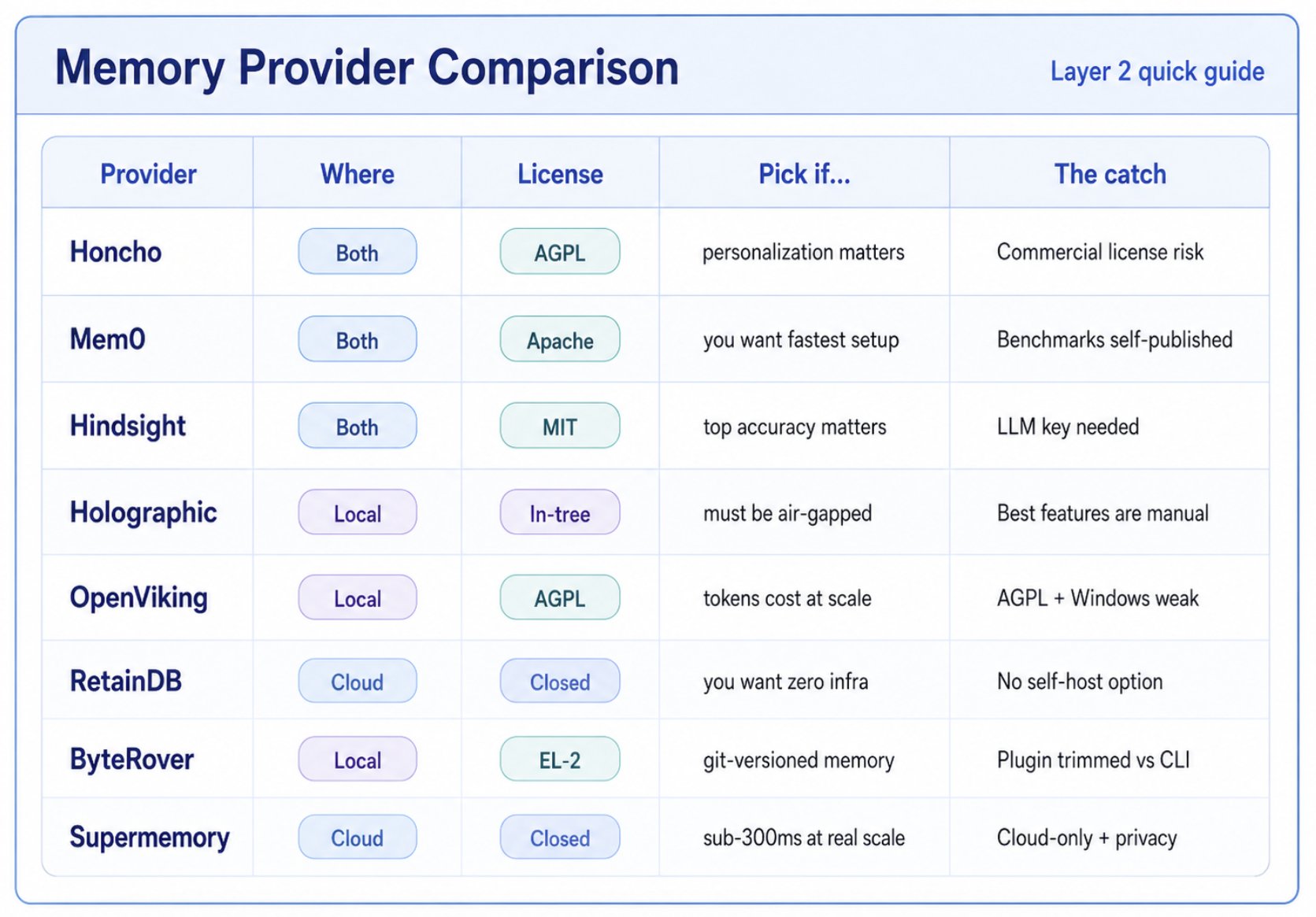
The 8 Official Providers
Honcho (Plastic Labs) - AI-native dialectic user modeling
The only provider in the lineup that tries to model how you think, not just what you said. Instead of storing flat facts like "Kevin uses 4-space indents," Honcho runs a multi-step reasoning pass after your conversations to build a profile of your reasoning patterns, preferences, and goals.
That profile evolves over time, so the agent gets better at anticipating what you'd want even on topics you've never discussed. It also lets multiple "AI identities" share the same view of you - useful if you run different specialist agents for coding, writing, and strategy and want all of them to know your style. Most-cited favorite in the Hermes Discord (@offendingcommit: "I've tried them all... I freakin' love Honcho.").
Mem0 - fastest 30-second setup, broadest ecosystem
The "just give me memory and stop asking questions" pick. You sign up for Mem0 cloud, paste an API key, and you're done - the provider extracts facts from conversations, deduplicates them, and serves up semantic search automatically in the background.
It's also the exclusive memory provider for AWS's Strands Agents SDK, which gives it the widest ecosystem reach in the lineup. In April 2026 Mem0 shipped a "v3" algorithm claiming to leapfrog Hindsight on benchmarks (94.8 on LongMemEval, 91.6 on LoCoMo).
Hindsight (Vectorize.io) - the benchmark king
The first memory system of any kind to publicly cross 90 on LongMemEval (91.4, December 2025). Hindsight thinks about memory as four separate networks - things about the world, things that happened, opinions, and raw observations - and pulls only a handful of high-value facts from each conversation (2 to 5, not one per sentence).
When you ask it something, it runs four different retrieval strategies in parallel - keyword search, vector similarity, graph traversal across related entities, and a recency pass - then fuses the results. That's how it gets the best recall accuracy in the published lineup.
It's also the only provider with a reflect tool that lets the agent run a reasoning pass over its own memory. That's uniquely valuable if you're running multiple agents on a shared memory bank and you need an orchestrator to synthesize what all of them know.
Holographic - zero-dependency, fully local, air-gapped
The only provider in the lineup that needs no internet, no API key, and no LLM to function. Everything lives in a local SQLite file. It uses a 1991-era technique called Holographic Reduced Representations to do compositional reasoning over facts - you can bind concepts together algebraically and probe for related ones later. Retrieval is sub-millisecond because it's pure local SQL.
OpenViking - tiered filesystem context DB
Your memory lives as files in a directory tree on your disk. You can cat them, grep them, edit them by hand. Each piece of stored knowledge has three loading tiers: a one-sentence summary, a paragraph-level overview, and the full content.
When the agent recalls something, it starts cheap (summaries only) and only loads the deeper tiers if the summary looks relevant. That structure is important if you're cost-sensitive at scale or you want memory you can read and edit like normal files.
RetainDB - cheapest paid tier, lowest friction
$20/month for 100,000 queries, with a free tier of 10,000 operations to test. The only provider in the lineup that's cloud-only at every price point (no self-host even on enterprise). The hook is convenience: you operate no infrastructure, RetainDB handles everything, and there's a "Memory Router" mode that intercepts your LLM calls and adds memory transparently with one config line.
Pick this option if you want shared memory across team members or agents and you don't want to operate a database.
ByteRover - memory as a git repo
Your memory is plain markdown files in a .brv/context-tree/ directory - grep-able, version-controllable, no database to run. ByteRover layers a 5-tier retrieval system on top, and four of those tiers don't need an LLM call, so most lookups finish in under 100ms with zero token spend.
The key selling point: you can branch, merge, and roll back memory like code with CLI commands. It also uses a special hook to extract high-value insights before Hermes compresses context, which is the cleanest fix in the lineup for the "agent loses memory after restart" failure mode (noted in issue #17251).
Supermemory - latency + scale leader
Sub-300ms recall sustained at over 100 billion tokens per month. Supermemory built a custom vector graph engine for this rather than stapling a vector DB and a graph DB together.
Its standout feature is context fencing: it automatically strips already-recalled memories out of conversations before storing them, which kills the "memory feedback loop" where auto-capture systems start re-ingesting their own outputs into the next round of memory.
Good choice if you want to operate at real scale (consumer app, multi-tenant SaaS, agent platform) and latency matters, but likely overkill for normal consumer use.
Here's a comparative look across all 8
Layer 3: Community plug-ins worth knowing
If none of the official 8 fits your use case, or if you want even more on top, the community has built another layer of memory tooling for Hermes. About five of these are production-quality enough to consider seriously, plus a longer tail of experiments to keep eyes on.
Two things to know up front about Layer 3:
Not every Layer 3 project competes with Layer 2. Some are alternative MemoryProvider plug-ins you'd pick instead of one of the official 8 (Mnemosyne is the clearest example). Others occupy a different role entirely - they store a different type of memory and run alongside your Layer 2 provider, not in place of it (GBrain is the clearest example, storing world facts about people, companies, and projects in a separate brain layer while your Layer 2 provider handles operational memory).
You give up polish to get capability. The official 8 ship with Nous's review and tend to "just work." Community plug-ins are typically a bit rougher on the install, have fewer docs, and more chance of hitting a bug. But they unlock things the official set doesn't offer like fully-local sub-millisecond retrieval (Mnemosyne), a markdown-and-Postgres knowledge graph that builds itself with zero LLM calls (GBrain), explainable retrieval rankings (yantrikdb), and cross-agent memory portability (PLUR).
The safe path if you're committing to a memory stack for real work: start with one of the official 8 and only reach for Layer 3 when you've identified a specific capability gap a community project fills. The standouts below are GBrain and Mnemosyne.
GBrain (by garrytan) - this is what I personally use
Open-sourced in April, MIT licensed, ~18k+ stars. TypeScript. Built by Garry Tan to run his own production agents. GBrain is structurally different from the official 8. GBrain does not subclass MemoryProvider, it plugs in as skillpack + MCP server (~30 MCP tools), and occupys a different ontological slot. The explicit doctrine in docs/guides/brain-vs-memory.md:
What makes it special:
Not just RAG: a full 8-layer knowledge engine for dramatically better memory and recall
Epistemology layer: tracks “who said what, when, and with what confidence” so no more hallucinated facts or lost context
Self-wiring knowledge graph: automatically extracts entities and creates real relationships (e.g., “attended,” “works_at,” “invested_in,” “founded”) with zero extra LLM calls
Dream cycles for autonomous synthesis: runs overnight (or on-demand) so your brain literally gets smarter while you sleep
Hybrid search done right: combines vector, keyword, RRF fusion, multi-query expansion, cosine reranking, compiled-truth boost, and backlink boost for far more accurate results than plain vector search
Specialized + versioned chunking: recursive markdown chunker (v4) that intelligently handles code blocks, frontmatter, transcripts, etc. so edits don’t break memory
Autonomous enrichment + persistent personal memory: tiered enrichment based on how often something is mentioned turning Hermes agent into a “clairvoyant” personal AI that actually knows you
Why pick GBrain over the official 8? If you want a graph cheap, git as system of record, overnight maintenance, you already have a markdown vault (migration covers Obsidian / Logseq / Notion / Roam), or you're building a "company of agents."
Mnemosyne (AxDSan/mnemosyne)
The strongest community alternative when you want a real MemoryProvider plug-in (rather than GBrain, which plays a different role). Runs entirely on your machine - no cloud, no API key, no internet - and recall is fast enough to feel instant (under 2 milliseconds in published tests).
What makes Mnemosyne interesting is its tiered memory architecture, modeled loosely on how humans handle short-term vs long-term memory. There's a "working" tier for what's actively relevant right now, an "episodic" tier for time-stamped events you might want to look up later, and a "scratchpad" for things still being considered for promotion. A consolidation pass runs periodically in the background to move useful items into long-term memory and prune the noise.
The standout feature for serious users: memory has a sense of time. You can ask "what did I believe about X last Tuesday?" and get back the agent's understanding as it was at that point, not as it is today. No other Hermes plug-in does this as cleanly. One soft adoption signal worth noticing: Mnemosyne is the only community memory plug-in that someone has bothered to write a dedicated Hermes skill wrapper for (a small file that teaches the agent how to use it intelligently). Nobody's done that for the others.
Others worth knowing about
Ladybug Memory - the local-only option with built-in importance ranking. Every memory gets a score from 1 to 10 so the system surfaces the things that matter first instead of treating everything equally. Pick it if you want fully-local memory and the built-in MEMORY.md cap is too small for your knowledge.
yantrikdb - the one to pick when you need to know why the agent recalled what it did. Every retrieval comes back with a "why retrieved" explanation, which is useful for debugging when the agent surfaces the wrong thing or for high-trust contexts where you need to audit what's shaping the agent's responses. Runs embedded out of the box, no separate database to manage.
hermes-agentmemory - a community fix for a real Hermes problem: when you tell the agent to forget something, it doesn't actually forget - it keeps an internal summary that quietly influences future recall. This provider does real deletion (gone is gone) and logs every memory operation so you can audit what happened. Pick it if compliance, privacy, or user-controlled forgetting matters.
PLUR - the cross-agent memory bridge. Hermes memory normally doesn't reach Cursor, and Cursor's doesn't reach Claude Code. PLUR stores everything in a shared .plur/ folder that all of them can read, so a fact you teach one agent automatically shows up in the others. Pick it if you work across multiple agents on the same project and don't want to teach each one separately.
FlowState-QMD - The "guess what you'll need next" provider. It tries to predict the agent's next likely query and warms up that memory in advance, so by the time the agent actually searches, the result is already cached and responses come back faster. Pick it if your agent does repetitive long-horizon work where the next step is usually guessable from context.
One thing I expected to find that doesn't exist: memory-as-skill is effectively a non-pattern. The agentskills.io standard means a "skill" could in principle implement memory. In practice all credible persistent memory flows through the MemoryProvider ABC. Even skills that "do memory" (the Mnemosyne SKILL.md, for instance) are wrappers around plug-ins, telling the agent how to use them.
How to actually pick?
Step 1: pick your layer strategy
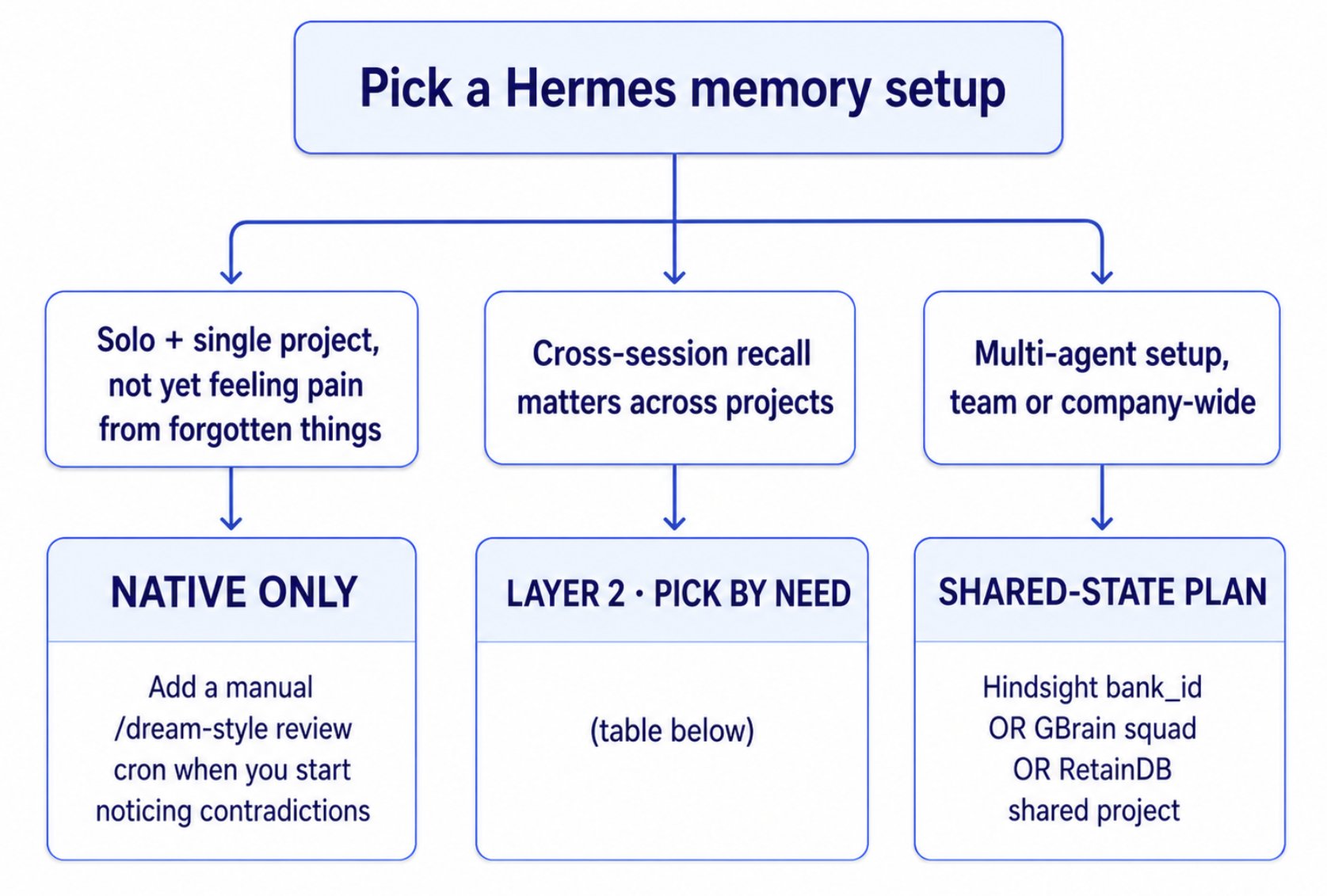
Step 2: pick your layer 2 system

Warning signs you went too heavy:
The agent feels noticeably slower. Responses that used to come back in about a second now take 3+ seconds. A heavy memory layer adds work on every turn, and once latency creeps past a few seconds the agent stops feeling responsive.
Your API bill is creeping up for the same usage. Memory operations consume tokens, and some providers fire extra background LLM calls every time you save something. If your usage patterns haven't changed but your spend has, suspect the memory layer.
The agent starts contradicting itself. It recalls one version of a fact in one session and the opposite in the next, and can't tell you which is right. This usually means memory is accumulating without ever being consolidated - the agent is now drawing from a polluted well.
The agent runs out of context mid-conversation. A greedy memory layer eats into the same context budget your actual conversation needs. If you start seeing "context too long" errors, or the agent forgets what you told it five minutes ago, the memory layer is overspending its share.
Your work isn't actually getting better. This is the one that matters most. You added memory expecting more accurate, more personalized output. After a couple of weeks, can you point at a specific way the agent is genuinely better than before? If you can't, the memory layer isn't earning its complexity. Pull it.
Frequently asked questions
What are the layers of Hermes Agent memory?
Hermes Agent memory has three practical layers: native memory that ships with Hermes, one optional official MemoryProvider, and community plug-ins such as GBrain or Mnemosyne for specialized needs.
Which Hermes memory provider should I choose?
Start with native memory unless you need semantic recall, shared team memory, graph memory, or compliance-grade deletion. Then choose the provider that matches that specific gap rather than installing memory infrastructure by default.
Can Hermes Agent use GBrain with another MemoryProvider?
Yes. GBrain occupies a different knowledge-graph slot than the official MemoryProvider layer, so it can complement a Layer 2 provider that handles operational conversation memory.
I hope you enjoyed this Hermes Agent deep dive on all things memory. If you want to explore more within the Hermes ecosystem, check out hermesatlas.com and sign up for the Hermes Atlas newsletter to stay up to date on everything.